 |
 |
|||||
S2DaoリファレンスセットアップSeasar2と同様にJDK1.4以上が必要です。s2-dao-x.x.x.zipを解凍してできたs2daoディレクトリを、Eclipseで 「ファイル→インポート→既存のプロジェクトをワークスペースへ」でインポートしてください。Seasar2の必要なバージョンは、Wikiをご覧ください。 s2-dao-examples/src/main/java配下にサンプルもあります。 S2Daoとして必要なjarファイルは、1.0.41以降はlib/の下に全てそろっています。それ以前のバージョンは、Seasar2で必要なjarファイル全てとSeasar2の(s2-framework/s2-extension)本体が必要です。簡単に機能を試すことができるように、RDBMSとしてHSQLDBを用意しています。 lib/hsqldb.jarはHSQLDBを実行する上では必要ですが、本番では必要ありません。 lib/s2-framework-2.3.xx-sources.jarとs2-extension-2.3.xx-sources.jarは、Eclipse上でソースを参照するためのもので、動作には必要ありません。 libのjarファイル(hsqldb.jar以外)とsrcのj2ee.dicon(Seasar2.4の場合はjdbc.dicon)をCLASSPATHにとおせば、S2Daoを実行できます。Eclipseにインポートして使う場合は設定は不要です。 dao.dicondao.diconはS2Daoの動作を設定するファイルです。 設定を変更したい場合はdao.diconのリファレンスを参照してください。 j2ee.diconS2Pagerの機能を使用する場合には、j2ee.diconを修正する必要があります(v1.0.36以降はデフォルトで有効になっています)。 具体的な設定内容はS2Pagerのドキュメントを ご覧ください。 作成すべきファイルS2Dao機能を使用するにあたり、JavaBeans、Dao(.java)、diconファイル、SQLファイル(.sql)の作成が必要となります。
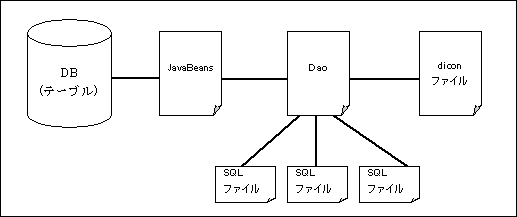
JavaBeansはテーブル、DaoはJavaBeans、diconファイルはDao、SQLファイルはDaoとそれぞれ関連しています。 JavaBeansJavaBeansはテーブルとの関連付けに使用します。 JavaBeansにテーブルの関連付けを行うには、以下の定数宣言とメソッドの実装が必要になります。
JavaBeansの構成と説明内で使用するテーブルは以下の通りです。 テーブル:EMP
テーブル:DEPT
TABLEアノテーションテーブルとの関連付けはTABLEアノテーションを使用します。 TABLEアノテーションは以下の形式で定数を宣言します。 - public static final String TABLE = “テーブル名”; EMPテーブルの場合以下のようになります。 public static final String TABLE = "EMP"; スキーマの定義をすることも可能です。スキーマ名が"SCOTT"の場合は以下のようになります。 public static final String TABLE = "SCOTT.EMP";※クラス名からパッケージ名を除いた名前がテーブル名と一致する場合は、TABLEアノテーションを定義する必要はありません。 また、dao.diconでorg.seasar.dao.impl.DecamelizeTableNamingを指定している場合、クラス名からパッケージ名を除いて、単語の区切りに_をつけて大文字にした名前がテーブル名と一致する場合は、TABLEアノテーションを定義する必要はありません。(1.0.44以降) COLUMNアノテーションテーブルのカラムとの関連付けはCOLUMNアノテーションを使用します。 - public static final String プロパティ名_COLUMN = "カラム名"; employeeNoというプロパティにEMPNOカラムを関連付けする場合以下のようになります。public static final String employeeNo_COLUMN = "EMPNO";※プロパティ名とカラム名から_(アンダースコア)を除いた名前が一致する場合は、COLUMNアノテーションを定義する必要はありません。 テーブルに存在しないプロパティは、自動的に無視されるので、特に何か定義する必要はありません。 N:1マッピングN:1マッピングとは、複数の従業員の行に1つの部署の行が関連付けられるような場合のマッピングです。 - public static final int プロパティ名_RELNO = 数値; RELNO定数は、N:1マッピングの連番です。 - public static final String プロパティ名_RELKEYS = "N側のテーブルのカラム名: 1側のテーブルのカラム名"; N:1マッピングのキーはRELKEYS定数で指定します。
キーが複数ある場合には、カンマ( , )で区切ります。例えば、mykey1:yourkey1, mykey2:yourkey2のようにします。 public static final int department_RELNO = 0; public static final String department_RELKEYS = "DEPTNUM:DEPTNO"; 1側のテーブルのカラム名がN側のテーブルのカラム名に等しい場合は、1側のテーブルのカラム名を省略することができます。 その場合以下のように定義することが出来ます。 public static final String department_RELKEYS = "DEPTNO"; また1側のテーブルのカラム名とN側のテーブルのカラム名に等しく、1側のテーブルのカラム名がプライマリーキーの場合、RELKEYS定数を省略することができます。 IDの自動生成ID(プライマリーキー)をRDBMSに自動生成させて、自動生成された値をBeanに自動的に設定することが出来ます。 そのために使うのが、IDアノテーションです。 バージョン1.0.47からは複数のプロパティにIDアノテーションを指定できるようになりました。 複数の指定をした場合、Beanは複合主キーを持ったテーブルと関連づいているとみなされます。 IDアノテーションは、プロパティ名_ID = "identity"のように指定します。 public static final String id_ID = "identity"; SEQUENCEを使うことも出来ます。myseqの部分は、実際のSEQUENCEに置き換えてください。 public static final String id_ID = "sequence, sequenceName=myseq";
SEQUENCEを使う場合、バージョン1.0.47以降では public static final String id_ID = "sequence, sequenceName=myseq, allocationSize=10"; 手動でIDを設定する場合は、何も指定する必要がありません。テーブルのプライマリーキーだという情報は、テーブルの定義(JDBCのメタデータ)より自動的に取得されます。また、明示的にassignedを指定することもできます。 public static final String id_ID = "assigned"; IDアノテーションを、RDBMSごとに切り替えて使うことができます(1.0.41以降)。例えば、Identityにのみ対応するMySQLではIdentityを使い、SEQUENCEにのみ対応するOracleではSEQUENCEを使うことができます。 public static final String id_mysql_ID = "identity"; public static final String id_oracle_ID = "sequence, sequenceName=myseq"; 指定したRDB以外のデフォルト値を指定することもできます。(1.0.41以降) public static final String id_mysql_ID = "identity"; public static final String id_ID = "sequence, sequenceName=myseq"; RDBMSのサフィックスと、使用できるIDの取得方法は、表の通りです。
VALUE_TYPEアノテーションJavaのプロパティとデータベースのカラムの型のマッピングはS2Daoにより自動で行われますが、VALUE_TYPEアノテーションを使うことで、明示的に指定することも可能です。 VALUE_TYPEアノテーションに指定するコンポーネントは自作することも可能ですが、よく利用されるものはorg.seasar.dao.types.ValueTypesクラスに定数としてあらかじめ定義されています。 ValueTypesクラスの定数を以下の表に示します。
この定数の利用法については、以下のCLOB型とのマッピング例を参照ください。 CLOB型とのマッピング例JavaBeansのString型プロパティをテーブルのCLOB型と対応付けるには、次のようにVALUE_TYPEアノテーションを使用します。
// JavaBeans
public static String aaa_VALUE_TYPE = "stringClobType";
private String aaa;
public String getAaa() {
return aaa;
}
public void setAaa(String aaa) {
this.aaa = aaa;
}
diconファイルでは、OGNL式を使用して、ValueTypesクラスの定数を参照します。 コンポーネント名とVALUE_TYPEアノテーションの値(ここでは"stringClobType")は一致させる必要があります。
<!-- xxx.dicon -->
<component name="stringClobType">
@org.seasar.dao.types.ValueTypes@CLOB
</component>
永続化されないカラムカラムが永続化の対象かどうかという情報は、テーブルの定義(JDBCのメタデータ)より自動的に取得されます。また、明示的にNO_PERSISTENT_PROPSを使って永続化したくないカラムを指定することもできます。NO_PERSISTENT_PROPSに空文字を指定するとJDBCのメタデータのメタデータを使わずにすべてのプロパティを永続化の対象とみなします。 public static final String NO_PERSISTENT_PROPS = "dummy1, dummy2"; VERSION_NO_PROPERTYアノテーションversionNoによる排他制御用のプロパティ名をデフォルトのversionNoから変えるときに使うのがVERSION_NO_PROPERTYアノテーションです。次のように使います。 public static final String VERSION_NO_PROPERTY = "myVersionNo"; TIMESTAMP_PROPERTYアノテーションtimestampによる排他制御用のプロパティ名をデフォルトのtimestampから変えるときに使うのがTIMESTAMP_PROPERTYアノテーションです。次のように使います。 public static final String TIMESTAMP_PROPERTY = "myTimestamp"; カラムに対応するインスタンス変数の宣言カラムの値はBeanのインスタンス変数で表します。インスタンス変数の宣言の方法には2種類あります。JavaBeansのプロパティとして宣言する方法テーブルのカラムに対応したインスタンス変数とアクセッサメソッドが必要です。 アクセッサメソッドの名前はJavaBeansの命名規約に従い以下の形式になります。 getterメソッド- public 型 getプロパティ名() setterメソッド- public void setプロパティ名(引数) NUMBER型のEMPNOというカラムの場合、プロパティとアクセッサは以下のように記述できます。(関連:COLUMNアノテーション)private long empno;
public long getEmpno() {
return empno;
}
public void setEmpno(long empno) {
this.empno = empno;
}
※カラムがNull可の場合、プリミティブ型を指定するとNullの際、0(ゼロ)が返されるのでNullを扱う場合は、 ラッパークラス(intならjava.lang.Integer)を指定して下さい。 以上の設定を行ったEMPテーブルに関連付くBeanは次のようになります。
public class Employee {
public static final String TABLE = "EMP";
public static final int department_RELNO = 0;
public static final String department_RELKEYS = "DEPTNUM:DEPTNO";
private long empno;
private String ename;
private Short deptnum;
private Department department;
public Employee() {
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
public Short getDeptnum() {
return deptnum;
}
public void setDeptnum(Short deptnum) {
this.deptnum = deptnum;
}
public long getEmpno() {
return empno;
}
public void setEmpno(long empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
}
publicフィールドとして宣言する方法バージョン1.0.47から、Seasar2.4と組み合わせた場合に、カラムに対応したインスタンス変数をpublicフィールドとして宣言できるようになりました。 アクセッサが不要になるため、Beanの記述が簡単になります。 この方法を使用した場合、EMPテーブルに関連付くBeanは次のように記述できます。
public class Employee {
public static final String TABLE = "EMP";
public static final int department_RELNO = 0;
public static final String department_RELKEYS = "DEPTNUM:DEPTNO";
public long empno;
public String ename;
public Short deptnum;
public Department department;
}
Dao(Data Access Object)Daoはインターフェースとして作成します。永続化されるデータとロジックを分離して、Dao本来の目的であるBeanの永続化を行います。 JavaBeansとは1:1の関係にあるので、一つのJavaBeansに対して一つのDaoを作成することになります。 Daoのメソッドを呼ぶことにより、メソッドに対応したSQLファイルに記述されているSQLが実行されます。 Daoを作成するには、以下の点が必要になります。
またメソッドの引数をSQL文で参照したり、WHERE句、ORDER句を追加、更新のSQLに含めない、あるいは含めるプロパティを指定する場合には、以下のアノテーションを使います。 メソッドの命名規約Daoのメソッドの名前は下の表にあげた名前で始まっている必要があります。 命名規約を変更したい場合は、dao.diconのリファレンスの「DaoNamingConventionImpl」を参照してください。
BEANアノテーションDaoがどのJavaBeans(エンティティ)に関連付けられているのかはBEANアノテーションで指定します。
バージョン1.0.46以降では、PROCEDUREアノテーションやSQLファイルを利用するメソッドのみが定義されたDaoに限りこのアノテーションの指定は不要です。 - public static final Class BEAN = JavaBeans名.class; EmployeeDaoクラスがEmployeeエンティティに関連付けられる場合は次のように定義します。 public static final Class BEAN = Employee.class; ARGSアノテーションメソッドの引数をSQL文で参照できるように、ARGSアノテーションを使用し、メソッドの引数名を指定します。メソッドの引数名は、リフレクションで取得できないためです。 - public static final String メソッド名_ARGS = "引数名"; public Employee getEmployee(int empno)というメソッドがDaoに定義されていた場合の引数名は次のように定義します。 public static final String getEmployee_ARGS = "empno"; メソッドの引数がテーブルのカラム名に対応している場合、引数名にはテーブルのカラム名を指定します。例えば、メソッドの引数名がempnoで、テーブルのカラム名がemployeenoの場合は、employeenoを指定するということです。 引数が複数ある場合には、カンマで区切ります。 引数がDTOの場合にはARGSアノテーションを省略できます。また、SQLファイル、SQLアノテーション、QUERYアノテーションのいずれかを使用するメソッドで、引数が1つの場合もARGSアノテーションを省略できます。 QUERYアノテーション自動的に生成されるSELECT文やDELETE文(DELETE文は1.0.44以降)にWHERE句やORDER BY句を追加するには、QUERYアノテーションを使用します。 - public static final String メソッド名_QUERY = "WHERE句ORDER BY句"; 引数で給与の上限と下限を指定し、その間に含まれる従業員を抽出する場合、次のようにします。 public static final String getEmployeesBySal_QUERY = "sal BETWEEN ? AND ? ORDER BY empno"; public List getEmployeesBySal(Float minSal, Float maxSal); 上記例の“?”をバインド変数と言います。バインド変数をQUERYアノテーションに記述することにより、メソッドの引数の値が順に”?”の部分に代入されます。 ARGSアノテーションは、必要ありません。ORDER BY句だけを記述するときは、ORDER BYで始めてください。SQLコメントも記述することが出来ます。 SQLコメントを使用したサンプルは以下のとおりです。 public static final String getEmployees_QUERY =
"job = /*job*/'CLERK'/*IF deptno != null*/ AND deptno = /*deptno*/20/*END*/";
上記サンプルは、引数deptnoがnullでない場合、deptnoが引数の値と一致するという条件を追加します。SQLコメントについての詳しい説明は、SQLコメントの項目を参照して下さい。 メソッドの定義Daoに定義したメソッドを呼ぶことにより、対応するSQLファイルに記述されているSQLが実行されますが、 更新(INSERT, UPDATE, DELETE)、検索処理ごとにメソッドの命名規約があります。 S2Daoではメソッドの命名規約よりSQL文の中身を自動的に決定しています。 また、定義するメソッドのオーバーロードはサポートしていません。
INSERT処理を行なうメソッドの名前が、insert,add,createではじまる必要があります。
戻り値はvoidあるいはintを指定してください。
intの場合、更新した行数が戻り値となります。引数の型はエンティティの型と一致させます。 public void insert(Department department); public int addDept(Department department); public void createDept(Department department); UPDATE処理を行うメソッドの名前が、update,modify,storeではじまる必要があります。
戻り値はvoidあるいはintです。intの場合、更新した行数が戻り値となります。引数の型はエンティティの型と一致させます。 public int update(Department department); public int modifyDept(Department department); public void storeDept(Department department); v1.0.37からはメソッド名の末尾にUnlessNullが付いているUPDATE処理の場合、引数に渡されたBeanのフィールドのうち、
nullでは無い値のみを更新対象とします(バッチ処理の場合はこの機能は使えません)。 public int updateUnlessNull(Department department); v1.0.40からはメソッド名の末尾にModifiedOnlyが付いているUPDATE処理の場合、
引数に渡されたBeanのフィールドのうち、変更した(setterを呼んで変更した)フィールドのみが更新対象となります。(バッチ処理の場合はこの機能は使えません)
ModifiedOnlyは、dao.diconファイルの設定により変更することができます。
設定を変更するにはdao.diconのリファレンスの「DaoNamingConventionImpl」を参照してください。 public int updateModifiedOnly(Emp emp); DELETE処理を行うメソッドの名前が、delete,removeではじまる必要があります。
戻り値はvoidあるいはintです。
intの場合、更新した行数が戻り値となります。引数の型はエンティティの型と一致させます。 public void delete(Department department); public int removeDept(Department department); 検索処理を行ないたい場合は、戻り値の型を指定します。戻り値の型がjava.util.Listを実装している場合、SELECT文でエンティティのリストを返します。 戻り値がエンティティ型の配列である場合、エンティティ配列を返します。戻り値の型がエンティティの型の場合、エンティティを返します。 public List selectList(int deptno); public Department[] selectArray(int deptno); v1.0.43からは検索処理の戻り値としてエンティティの他にDTOやMapが利用可能です。 戻り値がDTO型のリスト(List<Dto>)である場合、DTOのリストを返します。 戻り値がDTO型の配列(Dto[])である場合、DTOの配列を返します。 戻り値がMap型のリスト(List<Map>)である場合、Mapのリストを返します。 戻り値がMap型の配列(Map[])である場合、Mapの配列を返します。 public List<EmpDto> selectAsDtoList(int deptno); public EmpDto[] selectAsDtoArray(int deptno); public List<Map> selectAsMapList(int deptno); public Map[] selectAsMapArray(int deptno); それ以外の場合、SELECT count(*) FROM empのように1行で1のカラムの値を返すというようにS2Daoは想定します。 public int selectCountAll(); NO_PERSISTENT_PROPSアノテーション更新するときに、このプロパティは、SQLに含めて欲しくないという場合もあります。 そのような場合は、NO_PERSISTENT_PROPSアノテーションを使います。 public static final String insert_NO_PERSISTENT_PROPS = "sal, comm"; 上記のように指定すると、insertメソッドで、salとcommプロパティは永続化の対象になりません。 PERSISTENT_PROPSアノテーション更新するときに、このプロパティだけをSQLに含めたいという場合もあります。 そのような場合は、PERSISTENT_PROPSアノテーションを使います。 public static final String insert_PERSISTENT_PROPS = "deptno"; 上記のように指定すると、insertメソッドで、プライマリーキー、versionNo、timestampのプロパティに加えて、 PERSISTENT_PROPSアノテーションで指定したプロパティが永続化の対象になります。 SQLアノテーションバージョン1.0.28より、SQLアノテーションを使用することが可能です。機能はSQLファイルと同様で、アノテーションにてSQL及びSQLコメントを使用することが可能です。 SQLアノテーションに命名規約があります。
SQLアノテーションとDaoに定義したメソッドの関連付けをするには、SQLアノテーションを以下の形式にする必要があります。 - メソッド名_SQL examples.dao.EmployeeDao#getAllEmployees()に対応するSQLアノテーションは以下のようになります。public static final String getAllEmployees_SQL = "SELECT emp.*, dept.dname dname_0, dept.loc loc_0 FROM emp, dept WHERE emp.deptno = dept.deptno ORDER BY emp.empno;"; DBMSごとに使用するSQLアノテーションを指定することができます。 どのDBMSを使っているのかはjava.sql.DatabaseMetadata#getDatabaseProductName()に応じて、S2Daoが自動的に判断しています。 S2DaoのほうでDBMSごとにサフィックスを決めているので、SQLアノテーションにサフィックスを追加します。 例えばオラクルの場合、サフィックスはoracleなので、「getAllEmployees_oracle_SQL」というSQLアノテーションになります。 DBMSとサフィックスの関係は以下の通りです。
PROCEDUREアノテーションバージョン1.0.31より、PROCEDUREアノテーションを使用することによりStoredProcedureやStoredFunctionを実行することができます(バージョン1.0.47以降では代わりにPROCEDURE_CALLアノテーションを使用することをお勧めします)。PROCEDUREアノテーションは以下の形式のうちいずれかを指定します。 - public static final String メソッド名_PROCEDURE = "カタログ名.スキーマ名.プロシージャ名"; - public static final String メソッド名_PROCEDURE = "スキーマ名.プロシージャ名"; - public static final String メソッド名_PROCEDURE = "プロシージャ名"; - public static final String メソッド名_PROCEDURE = "パッケージ名.プロシージャ名";(Oracle/1.0.41以降) - public static final String メソッド名_PROCEDURE = "スキーマ名.パッケージ名.プロシージャ名";(Oracle/1.0.41以降)
PROCEDUREアノテーションでは、 また、DBMSやJDBCドライバの実装によっては、利用できない場合があります。
PROCEDURE_CALLアノテーションバージョン1.0.47で導入されました。このアノテーションはPROCEDUREアノテーションを使用したプロシージャ呼び出しの問題点を解消しています。 PROCEDUREアノテーションを使用したプロシージャ呼び出しには次の問題点がありました。
PROCEDURE_CALLアノテーションを使用したプロシージャ呼び出しは上記の問題に対し次のように対応しています。
PROCEDURE_CALLアノテーションは次のように指定してください。 - public static final String メソッド名_PROCEDURE_CALL = "プロシージャ名"; public static String hoge_PROCEDURE_CALL = "hogeProcedure"; public static String foo_PROCEDURE_CALL = "fooProcedure"; public Map hoge(); public void foo(FooDto dto); メソッドの引数は「なし」もしくは「DTOひとつ」でなければいけません。プロシージャがResultSetを返す場合には、戻り値を任意のDTOやDTOのList、Map等にすることができます。 ResultSetが返されない場合はvoidにしてください。 引数のDTOにはプロシージャのパラメータに対応するフィールドとパラメータのタイプを示すPROCEDURE_PARAMETERアノテーションを指定する必要があります。 PROCEDURE_PARAMETERアノテーションバージョン1.0.47で導入されました。このアノテーションはPROCEDURE_CALLアノテーションが指定されたメソッドの引数として使用されるDTO内に指定します。PROCEDURE_PARAMETERアノテーションは次のように指定してください。 - public static final String フィールド名_PROCEDURE_PARAMETER = "プロシージャのパラメータのタイプ名";
public static class FooDto {
public static String aaa_PROCEDURE_PARAMETER = "return";
public static String bbb_PROCEDURE_PARAMETER = "in";
public static String ccc_PROCEDURE_PARAMETER = "inout";
private double aaa;
private double bbb;
private double ccc;
//...
}
PROCEDURE_PARAMETERのタイプ名に指定できる値は この機能では、ソースコード上に記述したフィールドの順番と、 コンパイルされた.classファイル内のフィールドの順番が同じになることを前提としていますが、 これはJavaの仕様では保証されていません。 SunのJDKやEclipseではソースコード上と.classファイル内のフィールド順は同じになっていますが、 フィールドの順番が変わってしまう環境ではストアドの呼び出しが失敗します。 フィールドの順番が変わってしまう環境があった場合はSeasar-userメーリングリストまでお知らせください。 CHECK_SINGLE_ROW_UPDATEアノテーションバージョン1.0.47からCHECK_SINGLE_ROW_UPDATEアノテーションを使うことで、自動生成した更新SQLの実行後に、 更新行数のチェックをするかしないか選択できます。 CHECK_SINGLE_ROW_UPDATEアノテーションにfalseを指定すると、1行も更新できなかったとしてもNotSingleRowUpdateRuntimeExceptionを発生させないように設定できます。 CHECK_SINGLE_ROW_UPDATEアノテーションは、Dao全体またはメソッド単位に指定可能です。
// Dao全体の更新行数チェックをoffにする例
public interface HogeDao {
public static final boolean CHECK_SINGLE_ROW_UPDATE = false;
// ...
public interface FugaDao {
// メソッド単位で更新行数チェックをoffにする例
public static final boolean insert_CHECK_SINGLE_ROW_UPDATE = false;
insert(Fuga fuga);
// ...
diconファイルdiconファイルはDaoをコンテナにコンポーネント登録します。Dao機能を使用するには、登録したDaoに対して、AOPを適用する必要があります。 diconファイルはどこに配置してもいいのですが、通常Daoと同じ場所に配置します。なお、1.0.36以降はjarファイル内にdao.diconが含まれているため、デフォルトで使用する場合はdao.diconを配置する必要はないです。 diconファイルの詳しい設定方法については、DIContainerを参照して下さい。 S2DaoInterceptorの適用Dao機能を使用するにはorg.seasar.dao.interceptors.S2DaoInterceptorを登録したDaoに対してAOPを適用します。
<components>
<include path="dao.dicon"/>
<component class="example.dao.EmployeeDao">
<aspect>dao.interceptor</aspect>
</component>
</components>
dao.diconはS2Daoの動作を設定するファイルです。 詳細はdao.diconのリファレンスを参照してください。 SQLファイル検索、更新処理等を行うSQL文を記述します。 Daoに定義したメソッドを呼び出すと、対応するSQLファイルに記述されているSQL文が発行されます。 作成したSQLファイルはDaoと同じ場所に配置してください。 ※S2DaoにはSQLを自動で生成する機能が用意されているので、SQLファイルがない場合、S2DaoがSQL文を自動生成します。 SQLファイル名S2DaoにはSQLのファイル名にも命名規約があります。
作成したSQLファイルとDaoに定義したメソッドの関連付けをするには、SQLファイルのファイル名を以下の形式にする必要があります。 - Daoのクラス名_メソッド名.sql examples.dao.EmployeeDao#getAllEmployees()に対応するSQLファイルは以下のようになります。examples/dao/EmployeeDao_getAllEmployees.sql DBMSごとに使用するSQLファイルを指定することができます。 どのDBMSを使っているのかはjava.sql.DatabaseMetadata#getDatabaseProductName()に応じて、S2Daoが自動的に判断しています。 S2DaoのほうでDBMSごとにサフィックスを決めているので、SQLファイル名にサフィックスを追加します。 例えばオラクルの場合、サフィックスはoracleなので、「EmployeeDao_getAllEmployees_oracle.sql」というファイル名になります。 DBMSとサフィックスの関係は以下の通りです。
SQL文の記述SQLファイルには、”SELECT * FROM EMP”, “DELETE FROM EMP WHERE EMPNO = 7788”といった、普通のSQL文を記述することが可能です。 また、WHERE句の条件の値などを動的に変化させることも可能です。詳しくは、SQLコメントを参照して下さい。 SQL_FILEアノテーションバージョン1.0.43よりSQL_FILEアノテーションが導入されました。 SQLファイルを利用するDaoのメソッドにこのアノテーションを付けると、対応するSQLファイルが見つからない場合にS2Daoが例外を投げます。 記述の不備やSQLファイルの配置し忘れなどのミスを検出するために使用してください。 SQL_FILEアノテーションの書式は - public static final String メソッド名_SQL_FILE = null; となります。例えば、DaoのgetAllEmployeesメソッドがSQLファイルを利用する場合は次のように記述します。 public String getAllEmployees_SQL_FILE = null; public List getAllEmployees(); SQLファイルのパス指定バージョン1.0.47よりSQL_FILEアノテーションにSQLファイルのパスを指定できるようになりました。 これにより、Daoとは別の場所にファイルを配置することが出来るようになります。 パスは、絶対パスではなくクラスパス配下の相対パスを指定してください。 public String getAllEmployees_SQL_FILE = "resource/sqlfile/employee_all.sql"; public List getAllEmployees(); また、SQLファイルの複数DBMS対応もそのまま使えます。 例えば上の例でOracleに接続している場合、 Oracle用のSQLファイルである"resource/sqlfile/employee_all_oracle.sql"があれば、 そちらが優先的に利用されます。 SQLコメントS2Daoでは、メソッドの引数とSQL文のバインド変数の対応付けを/**/や--などのコメントを使って行います。 コメントなので、対応付けをした後でも、SQL*PlusなどのSQLのツールでそのまま実行することができます。 最初、SQLのツールでSQL文を実行して思い通りの結果を出力するようになったら、 それに対して、コメントを埋め込んでいくと良いでしょう。 また、SQL文に対しての説明の意味でのコメントを使用したい場合は、/*の後にスペースを入れることにより、 普通のコメントを使用することが出来ます。例として、/* hoge*/となります。/*の後にスペースが入っているので、実行時には無視されます。 バインド変数コメントDaoに定義したメソッドの引数の値をSQL文で使用する場合は、SQL文にバインド変数コメントを記述します。 バインド変数コメントの右側のリテラルに引数の値が自動的に置換され実行されます。 バインド変数コメントは、以下のように記述します。 - /*引数名*/リテラル 引数がJavaBeansの場合は以下のように記述します。 - /*引数名.プロパティ名*/リテラル 引数名はDaoに設定したARGSアノテーションの値と揃える必要があります。 (ただし引数が一つの場合は、その制約はありません。) public String getEmployee_ARGS = "empno"; public Employee getEmployee(int empno); Daoに上記のメソッドを定義した場合、SQLファイル(EmploeeDao_getEmployee.sql)は次のようにバインド変数を使用することが可能です。自動的にgetEmployeeメソッドの引数の値が設定されます。 SELECT * FROM emp WHERE empno = /*empno*/7788 IN句にバインド変数を適用したい場合は以下のようにすることができます。 - IN /*引数名*/(...) IN /*names*/('aaa', 'bbb')
引数はjava.util.Listや配列の引数となります。上記のIN句の場合は、以下のように引数を用意します。 String[] names = new String[]{"SCOTT", "SMITH", "JAMES"};
String配列namesが自動的にバインド変数の部分に置換されます。 LIKEを使用する場合は、次のようにします。 ename LIKE /*ename*/'hoge' ワイルドカードを使いたい場合は、メソッドの引数の値に埋め込みます。 「"COT"を含む」という条件を指定する場合は、以下のように引数の値にワイルドカードを埋め込みます。 employeeDao.findEmployees("%COT%");
埋め込み変数コメントDaoに定義したメソッドの引数の値をSQL文に文字列として直接埋め込む場合は、SQL文に埋め込み変数コメントを記述します。 埋め込み変数コメントの右側のリテラルに引数の値が自動的に置換され実行されます。 埋め込み変数コメントは、以下のように記述します。 - /*$引数名*/リテラル 引数がJavaBeansの場合は以下のように記述します。 - /*$引数名.プロパティ名*/リテラル 埋め込み変数コメントを使用する場合、SQLインジェクションに対する対策はDaoの呼び出し側で行う必要があります。 IFコメントIFコメントでは、条件に応じて実行するSQL文を変えることが可能です。IFコメントは以下の形式で記述します。 - /*IF 条件*/ .../*END*/ サンプルは以下のとおりです。 /*IF hoge != null*/hoge = /*hoge*/'abc'/*END*/ IFコメントは、条件が真の場合、/*IF*/と/*END*/に囲まれた部分が評価されます。
上記の場合、引数hogeがnull出ない場合にのみ、IFコメントで囲まれている部分(hoge = /*hoge*/'abc')が評価されます。
/*IF hoge != null*/hoge = /*hoge*/'abc' -- ELSE hoge is null /*END*/ 条件がfalseになると-- ELSEの後の部分(hoge is null)が評価されます。 BEGINコメントBEGINコメントは、WHERE句内のすべてのELSEを含まないIFコメントがfalseになった場合に、
WHERE句自体を出力したくない場合に使います。BEGINコメントはIFコメントと併せて使用します。 - /*BEGIN*/WHERE句/*END*/ サンプルは以下の通りです。/*BEGIN*/WHERE /*IF job != null*/job = /*job*/'CLERK'/*END*/ /*IF deptno != null*/AND deptno = /*deptno*/20/*END*/ /*END*/ 上記の場合、job,deptnoがnullの場合は、WHERE句は出力されません。 job == null,deptno != nullの場合は、WHERE depno = ?、 job != null,deptno == nullの場合は、WHERE job = ?、 job != null,deptno != nullの場合は、WHERE job = ? AND depno = ?のようになります。動的SQLも思いのままです。 EntityManagerを使用したQueryの実行EntityManagerを使用し、自動的に生成されるSELECT文にWHERE句やORDER BY句を追加できます。書き方は、QUERYアノテーションと同様です。 主に、動的にQueryを組み立てたいときに使用します。EntityManagerを使用するには、以下のクラスを継承します。 - org.seasar.dao.impl.AbstractDao Daoのインターフェース名は、必ず"Dao"で終わるようにしてください。S2Daoは、AbstractDaoを継承したクラスが実装しているインターフェースの中で、 クラス名が"Dao"で終わっているインターフェースをDaoインターフェースだと判断しているためです。 EntityManagerには、以下のメソッドが用意されています。
AbstractDaoを継承したクラスの基本的な実装方法
implementsするDaoのインターフェース名の最後は"Dao"で終了している必要があります。 org.seasar.dao.DaoMetaDataFactoryを引数とし、super(org.seasar.dao.DaoMetaDataFactory)を呼び出します。 EntityManagerで提供しているメソッドを使用する場合は、getEntityManager().find(...);のように、getEntityManager()メソッドを使用し、EntityManagerを取得し呼び出すことが出来ます。
package examples.dao;
import java.util.List;
import org.seasar.dao.DaoMetaDataFactory;
import org.seasar.dao.impl.AbstractDao;
public class Employee2DaoImpl extends AbstractDao implements Employee2Dao {
public Employee2DaoImpl(DaoMetaDataFactory daoMetaDataFactory) {
super(daoMetaDataFactory);
}
public List getEmployees(String ename) {
return getEntityManager().find("ename LIKE ?", "%" + ename + "%");
}
}
詳しい使用方法はEntityManagerを使用したExampleを参照して下さい。 更新SQLの自動生成更新SQL文を自動生成させるには、メソッド名を命名規約にあわせ、JavaBeansを1つ引数に持つメソッドを定義するだけです。 SQLファイルの作成は不要です。例としてInsertの場合、命名規約に合わせ、以下のように定義します。 public int insert(Department department); VersionNoによる排他制御S2Daoは排他制御も自動的に行うことができます。 例えば、2人のユーザがversionNo値0の同一データを取得して更新しようとした場合、 先に更新したユーザは正常に登録することができます。そのとき自動でversionNoはインクリメントされ、DBのversionNoは1となります。 次にもう1人のユーザがデータを更新しようとすると、ユーザが保持しているversionNoの値(0)と、 実際にDB格納されているversionNoの値(1)が異なることになり、NotSingleRowUpdatedRuntimeExceptionが発生し更新失敗することになります。 VersionNoの値によりinsertされたばかりのオブジェクトをとってきたものなのか、新規にnewされた永続化前のオブジェクトなのかを判断したい場合は、 JavaBeans上でversionNoを定義する時に初期値として-1を設定してください。 そうすることによってversionNo == -1が永続化前のオブジェクト、versionNo >= 0が永続化済みのオブジェクトという風に判断できるようになります。 Timestampによる排他制御VersionNoの他にTimestampによる排他制御もS2Daoが自動的に行うことができます。 Timestamp型でtimestampという名前のプロパティを定義するだけで、自動的に行ってくれます。 DaoからInsertする時に、new java.sql.Timestamp()をtimestampプロパティへセットしてInsert文を発行します。 更新(Update・Delete)時に、JavaBeansのtimestampプロパティ値とレコードのtimestampカラム値を比較し、 異なっている場合にはVersionNoと同様にNotSingleRowUpdatedRuntimeExceptionが投げられます。 更新時にTimestamp用のカラムの値にnullが設定されていると比較に失敗するので注意してください。 バッチ更新更新系のメソッドで次のように引数をエンティティのクラスの配列またはListにすると自動的に更新用のSQL文を生成し、バッチ更新をすることができます。 なお、バッチ更新の場合、IDの自動生成を行うことはできません。 また、versionNoやtimestampの設定がしてあっても、エンティティの値は更新後のデータベースと同じ値にはなりません。 バッチ更新後は、最新のエンティティをデータベースから再取得するようにしてください。 int insertBatch(Employee[] employees) バージョン1.0.47から以下のように戻り値の型をint[]にすることで、エンティティ毎に更新したレコード数を取得できます。 ただし、この戻り値はJDBCドライバが返す値そのものなので、ドライバによってはjava.sql.Statement#SUCCESS_NO_INFOしか取れないこともあります。 int[] insertBatch2(Employee[] employees) 検索SQLの自動生成メソッドのsignatueより、 S2Daoに自動的にSELECT文を生成させることもできます。ARGSアノテーションにカラム名を指定することで、引数の値によってWHERE句が変わるような動的なSQL文も自動生成できます。 SELECT * FROM emp /*BEGIN*/WHERE /*IF job != null*/job = /*job*/'CLERK'/*END*/ /*IF deptno != null*/AND deptno = /*deptno*/20/*END*/ /*END*/ 上記SQL文に相当するSQL文を自動生成するには以下のように定義します。上記SQLの/**/などについては、SQLコメントを参照してください。 public static final String getEmployeeByJobDeptno_ARGS = "job, deptno"; public List getEmployeeByJobDeptno(String job, Integer deptno); N:1でマッピングされているカラムを指定する場合には、「カラム名_関連番号」で指定します。 N:1でマッピングされているBeanは左外部結合を使って1つのSQL文で取得されます。左外部結合をサポートしていないRDBMSはSELECT文自動生成の対象外です。 オラクルのように左外部結合が標準と異なる場合も、S2DaoがRDBMSがオラクルであると自動的に判断して適切なSQL文を組み立てます。 引数にDTO(Data Transter Object)を指定することもできます。その場合、ARGSアノテーションを指定してはいけません。
S2Daoは、引数が1つで、ARGSアノテーションが指定されていない場合、引数をDTOとみなし、DTOのプロパティを使って自動的にSQL文を組み立てます。
プロパティ名とカラム名が異なる場合は、COLUMNアノテーションを使ってカラム名を指定します。N:1でマッピングされているカラムを指定する場合には、カラム名_関連番号で指定します。
テーブルに存在しないプロパティ(カラム)は自動的に無視されます。プロパティの値によって、WHERE句が変わるような動的SQL文を自動生成します。
package examples.dao;
public class EmployeeSearchCondition {
public static final String dname_COLUMN = "dname_0";
private String job;
private String dname;
...
}
List getEmployeesBySearchCondition(EmployeeSearchCondition dto); また同様の指定方法で引数にEntityを使用することも出来ます。DTOの詳しい使用方法は、自動で検索用SQL文を生成する場合のExampleを参照して下さい。
public class Employee implements Entity {
private long empno;
private String ename;
...
}
public interface GenericDao {
Object select(Entity entity);
List selectList(Entity entity);
}
public interface EmployeeDao extends GenericDao {
Class BEAN = Employee.class;
}
S2Daoの実行Daoを実行する基本的な方法は以下のようになります。
S2Daoではトランザクション制御は行なっていません、トランザクションについてはトランザクションの自動制御を参照して下さい。 実行クラスサンプル
package examples.dao;
import org.seasar.framework.container.S2Container;
import org.seasar.framework.container.factory.S2ContainerFactory;
public class EmployeeDaoClient {
private static final String PATH = "examples/dao/EmployeeDao.dicon";
public static void main(String[] args) {
S2Container container = S2ContainerFactory.create(PATH); /* 手順1 */
container.init();
try {
EmployeeDao dao = (EmployeeDao) container.getComponent(EmployeeDao.class);/* 手順2 */
System.out.println(dao.getAllEmployee(7788));/* 手順3 */
} finally {
container.destroy();
}
}
}
ExampleこのExampleは前提条件として以下のテーブル、JavaBeans、dao.diconを使用します。 テーブル:EMP
テーブル:DEPT
EMPテーブルに関連付くJavaBeansは次の通りです。
package examples.dao;
import java.io.Serializable;
import java.sql.Timestamp;
public class Employee implements Serializable {
public static final String TABLE = "EMP";
public static final int department_RELNO = 0;
public static final String timestamp_COLUMN = "tstamp";
private long empno;
private String ename;
private String job;
private Short mgr;
private java.util.Date hiredate;
private Float sal;
private Float comm;
private int deptno;
private Timestamp timestamp;
private Department department;
public Employee() {
}
public Employee(long empno) {
this.empno = empno;
}
public long getEmpno() {
return this.empno;
}
public void setEmpno(long empno) {
this.empno = empno;
}
public java.lang.String getEname() {
return this.ename;
}
public void setEname(java.lang.String ename) {
this.ename = ename;
}
public java.lang.String getJob() {
return this.job;
}
public void setJob(java.lang.String job) {
this.job = job;
}
public Short getMgr() {
return this.mgr;
}
public void setMgr(Short mgr) {
this.mgr = mgr;
}
public java.util.Date getHiredate() {
return this.hiredate;
}
public void setHiredate(java.util.Date hiredate) {
this.hiredate = hiredate;
}
public Float getSal() {
return this.sal;
}
public void setSal(Float sal) {
this.sal = sal;
}
public Float getComm() {
return this.comm;
}
public void setComm(Float comm) {
this.comm = comm;
}
public int getDeptno() {
return this.deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
public Timestamp getTimestamp() {
return this.timestamp;
}
public void setTimestamp(Timestamp timestamp) {
this.timestamp = timestamp;
}
public Department getDepartment() {
return this.department;
}
public void setDepartment(Department department) {
this.department = department;
}
public boolean equals(Object other) {
if (!(other instanceof Employee))
return false;
Employee castOther = (Employee) other;
return this.getEmpno() == castOther.getEmpno();
}
public String toString() {
StringBuffer buf = new StringBuffer();
buf.append(empno).append(", ");
buf.append(ename).append(", ");
buf.append(job).append(", ");
buf.append(mgr).append(", ");
buf.append(hiredate).append(", ");
buf.append(sal).append(", ");
buf.append(comm).append(", ");
buf.append(deptno).append(", ");
buf.append(timestamp).append(" {");
buf.append(department).append("}");
return buf.toString();
}
public int hashCode() {
return (int) this.getEmpno();
}
}
DEPTテーブルに関連付くJavaBeansは次の通りです。
package examples.dao;
import java.io.Serializable;
public class Department implements Serializable {
public static final String TABLE = "DEPT";
private int deptno;
private String dname;
private String loc;
private int versionNo;
public Department() {
}
public int getDeptno() {
return this.deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
public java.lang.String getDname() {
return this.dname;
}
public void setDname(java.lang.String dname) {
this.dname = dname;
}
public java.lang.String getLoc() {
return this.loc;
}
public void setLoc(java.lang.String loc) {
this.loc = loc;
}
public int getVersionNo() {
return this.versionNo;
}
public void setVersionNo(int versionNo) {
this.versionNo = versionNo;
}
public boolean equals(Object other) {
if (!(other instanceof Department))
return false;
Department castOther = (Department) other;
return this.getDeptno() == castOther.getDeptno();
}
public String toString() {
StringBuffer buf = new StringBuffer();
buf.append(deptno).append(", ");
buf.append(dname).append(", ");
buf.append(loc).append(", ");
buf.append(versionNo);
return buf.toString();
}
public int hashCode() {
return (int) this.getDeptno();
}
}
各Exampleでincludeしているdao.diconは以下の通りです。
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE components PUBLIC "-//SEASAR//DTD S2Container//EN"
"http://www.seasar.org/dtd/components.dtd">
<components namespace="dao">
<include path="j2ee.dicon"/>
<component
class="org.seasar.dao.impl.DaoMetaDataFactoryImpl"/>
<component name="interceptor"
class="org.seasar.dao.interceptors.S2DaoInterceptor"/>
</components>
SQL文を記述する場合のExampleSQLファイルを作成し、Daoから記述したSQL文を実行する演習です。
Daoの作成
package examples.dao;
import java.util.List;
public interface EmployeeDao {
public Class BEAN = Employee.class;
public List getAllEmployees();
public String getEmployee_ARGS = "empno";
public Employee getEmployee(int empno);
public int getCount();
public String getEmployeeByJobDeptno_ARGS = "job, deptno";
public List getEmployeeByJobDeptno(String job, Integer deptno);
public int update(Employee employee);
}
SQLファイルの作成
SELECT emp.*, dept.dname dname_0, dept.loc loc_0 FROM emp, dept WHERE emp.deptno = dept.deptno ORDER BY emp.empnoEmployeeDao_getEmployee.sql SELECT emp.*, dept.dname dname_0, dept.loc loc_0 FROM emp, dept WHERE empno = /*empno*/7788 AND emp.deptno = dept.deptnoEmployeeDao_getCount.sql SELECT count(*) FROM empEmployeeDao_getEmployeeByJobDeptno.sql SELECT * FROM emp /*BEGIN*/WHERE /*IF job != null*/job = /*job*/'CLERK'/*END*/ /*IF deptno != null*/AND deptno = /*deptno*/20/*END*/ /*END*/EmployeeDao_update.sql UPDATE emp SET ename = /*employee.ename*/'SCOTT' WHERE empno = /*employee.empno*/7788 diconファイルの作成
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE components PUBLIC "-//SEASAR//DTD S2Container//EN"
"http://www.seasar.org/dtd/components.dtd">
<components>
<include path="dao.dicon"/>
<component class="examples.dao.EmployeeDao">
<aspect>dao.interceptor</aspect>
</component>
</components>
実行ファイルの作成
package examples.dao;
import java.util.List;
import org.seasar.framework.container.S2Container;
import org.seasar.framework.container.factory.S2ContainerFactory;
public class EmployeeDaoClient {
private static final String PATH = "examples/dao/EmployeeDao.dicon";
public static void main(String[] args) {
S2Container container = S2ContainerFactory.create(PATH);
container.init();
try {
EmployeeDao dao = (EmployeeDao) container
.getComponent(EmployeeDao.class);
List employees = dao.getAllEmployees();
for (int i = 0; i < employees.size(); ++i) {
System.out.println(employees.get(i));
}
Employee employee = dao.getEmployee(7788);
System.out.println(employee);
int count = dao.getCount();
System.out.println("count:" + count);
dao.getEmployeeByJobDeptno(null, null);
dao.getEmployeeByJobDeptno("CLERK", null);
dao.getEmployeeByJobDeptno(null, new Integer(20));
dao.getEmployeeByJobDeptno("CLERK", new Integer(20));
System.out.println("updatedRows:" + dao.update(employee));
} finally {
container.destroy();
}
}
}
実行結果
DEBUG 2004-10-12 11:07:01,117 [main] 物理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:01,133 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:01,914 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:07:02,742 [main] SELECT emp.*, dept.dname dname_0, dept.loc loc_0 FROM emp, dept
WHERE emp.deptno = dept.deptno ORDER BY emp.empno
DEBUG 2004-10-12 11:07:02,758 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:02,867 [main] 論理的なコネクションを閉じました
7369, SMITH, CLERK, 7902, 1980-12-17 00:00:00.0, 800.0, null, 20, 1980-12-17 00:00:00.0
{0, RESEARCH, DALLAS, 0}
7499, ALLEN, SALESMAN, 7698, 1981-02-20 00:00:00.0, 1600.0, 300.0, 30, 1980-12-17 00:00:00.0
{0, SALES, CHICAGO, 0}
7521, WARD, SALESMAN, 7698, 1981-02-22 00:00:00.0, 1250.0, 500.0, 30, 1980-12-17 00:00:00.0
{0, SALES, CHICAGO, 0}
7566, JONES, MANAGER, 7839, 1981-04-02 00:00:00.0, 2975.0, null, 20, 1980-12-17 00:00:00.0
{0, RESEARCH, DALLAS, 0}
7654, MARTIN, SALESMAN, 7698, 1981-09-28 00:00:00.0, 1250.0, 1400.0, 30, 1980-12-17 00:00:00.0
{0, SALES, CHICAGO, 0}
7698, BLAKE, MANAGER, 7839, 1981-05-01 00:00:00.0, 2850.0, null, 30, 1980-12-17 00:00:00.0
{0, SALES, CHICAGO, 0}
7782, CLARK, MANAGER, 7839, 1981-06-09 00:00:00.0, 2450.0, null, 10, 1980-12-17 00:00:00.0
{0, ACCOUNTING, NEW YORK, 0}
7788, SCOTT, ANALYST, 7566, 1982-12-09 00:00:00.0, 3000.0, null, 20, 2004-10-12 10:15:54.914
{0, RESEARCH, DALLAS, 0}
7839, KING, PRESIDENT, null, 1981-11-17 00:00:00.0, 5000.0, null, 10, 1980-12-17 00:00:00.0
{0, ACCOUNTING, NEW YORK, 0}
7844, TURNER, SALESMAN, 7698, 1981-09-08 00:00:00.0, 1500.0, 0.0, 30, 1980-12-17 00:00:00.0
{0, SALES, CHICAGO, 0}
7876, ADAMS, CLERK, 7788, 1983-01-12 00:00:00.0, 1100.0, null, 20, 1980-12-17 00:00:00.0
{0, RESEARCH, DALLAS, 0}
7900, JAMES, CLERK, 7698, 1981-12-03 00:00:00.0, 950.0, null, 30, 1980-12-17 00:00:00.0
{0, SALES, CHICAGO, 0}
7902, FORD, ANALYST, 7566, 1981-12-03 00:00:00.0, 3000.0, null, 20, 1980-12-17 00:00:00.0
{0, RESEARCH, DALLAS, 0}
7934, MILLER, CLERK, 7782, 1982-01-23 00:00:00.0, 1300.0, null, 10, 1980-12-17 00:00:00.0
{0, ACCOUNTING, NEW YORK, 0}
DEBUG 2004-10-12 11:07:02,883 [main] SELECT emp.*, dept.dname dname_0, dept.loc loc_0 FROM emp, dept
WHERE empno = 7788 AND emp.deptno = dept.deptno
DEBUG 2004-10-12 11:07:02,883 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:02,914 [main] 論理的なコネクションを閉じました
7788, SCOTT, ANALYST, 7566, 1982-12-09 00:00:00.0, 3000.0, null, 20, 2004-10-12 10:15:54.914
{0, RESEARCH, DALLAS, 0}
DEBUG 2004-10-12 11:07:02,914 [main] SELECT count(*) FROM emp
DEBUG 2004-10-12 11:07:02,914 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:02,914 [main] 論理的なコネクションを閉じました
count:14
DEBUG 2004-10-12 11:07:02,929 [main] SELECT * FROM emp
DEBUG 2004-10-12 11:07:02,929 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:02,945 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:07:02,945 [main] SELECT * FROM emp
WHERE
job = 'CLERK'
DEBUG 2004-10-12 11:07:02,945 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:02,961 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:07:02,961 [main] SELECT * FROM emp
WHERE
deptno = 20
DEBUG 2004-10-12 11:07:02,961 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:02,961 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:07:02,961 [main] SELECT * FROM emp
WHERE
job = 'CLERK'
AND deptno = 20
DEBUG 2004-10-12 11:07:02,961 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:03,008 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:07:03,023 [main] UPDATE emp SET ename = 'SCOTT'
WHERE empno = 7788
DEBUG 2004-10-12 11:07:03,023 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:07:03,023 [main] 論理的なコネクションを閉じました
updatedRows:1
DEBUG 2004-10-12 11:07:03,023 [main] 物理的なコネクションを閉じました
"updatedRows"の値から更新された件数を確認することができます。 自動で更新用SQL文を生成する場合のExample自動で更新処理(UPDATE, INSERT, DELETE)のSQL文の生成とVersionNoによる排他制御の演習です。SQLファイルの作成は不要です。
Daoの作成
package examples.dao;
public interface DepartmentDao {
public Class BEAN = Department.class;
public void insert(Department department);
public void update(Department department);
public void delete(Department department);
}
diconファイルの作成
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE components PUBLIC "-//SEASAR//DTD S2Container//EN"
"http://www.seasar.org/dtd/components.dtd">
<components>
<include path="dao.dicon"/>
<component class="examples.dao.DepartmentDao">
<aspect>dao.interceptor</aspect>
</component>
</components>
実行ファイルの作成
package examples.dao;
import org.seasar.framework.container.S2Container;
import org.seasar.framework.container.factory.S2ContainerFactory;
public class DepartmentDaoClient {
private static final String PATH = "examples/dao/DepartmentDao.dicon";
public static void main(String[] args) {
S2Container container = S2ContainerFactory.create(PATH);
container.init();
try {
DepartmentDao dao = (DepartmentDao) container
.getComponent(DepartmentDao.class);
Department dept = new Department();
dept.setDeptno(99);
dept.setDname("foo");
dao.insert(dept);
dept.setDname("bar");
System.out.println("before update versionNo:" + dept.getVersionNo());
dao.update(dept);
System.out.println("after update versionNo:" + dept.getVersionNo());
dao.delete(dept);
} finally {
container.destroy();
}
}
}
実行結果DEBUG 2004-09-09 19:22:10,588 [main] 物理的なコネクションを取得しました DEBUG 2004-09-09 19:22:10,588 [main] 論理的なコネクションを取得しました DEBUG 2004-09-09 19:22:11,447 [main] 論理的なコネクションを閉じました DEBUG 2004-09-09 19:22:11,603 [main] 論理的なコネクションを取得しました DEBUG 2004-09-09 19:22:11,603 [main] INSERT INTO DEPT (deptno, dname, versionNo, loc) VALUES(99, 'foo', 0, null) DEBUG 2004-09-09 19:22:11,666 [main] 論理的なコネクションを閉じました before update versionNo:0 DEBUG 2004-09-09 19:22:11,666 [main] 論理的なコネクションを取得しました DEBUG 2004-09-09 19:22:11,666 [main] UPDATE DEPT SET dname = 'bar', versionNo = versionNo + 1, loc = null WHERE deptno = 99 AND versionNo = 0 DEBUG 2004-09-09 19:22:11,666 [main] 論理的なコネクションを閉じました after update versionNo:1 DEBUG 2004-09-09 19:22:11,666 [main] 論理的なコネクションを取得しました DEBUG 2004-09-09 19:22:11,666 [main] DELETE FROM DEPT WHERE deptno = 99 AND versionNo = 1 DEBUG 2004-09-09 19:22:11,681 [main] 論理的なコネクションを閉じました DEBUG 2004-09-09 19:22:11,681 [main] 物理的なコネクションを閉じました 出力結果を見ると、自動的にSQL文が発行されていることが分かります。またJavaBeans(Department)にはint型のプロパティversionNoが定義してあるので、
自動でversionNoの値が+1され、この値によって排他制御されていることがわかります。
updateメソッドを呼ぶ以前では、versionNoの値は0ですが、updateメソッドを呼び出した後では、値が1になります。 自動で検索用SQL文を生成する場合のExample自動でSELECT文の生成とTimestampによる自動排他制御を行う演習です。SQLファイルの作成は不要です。また引数にDTOを使用するメソッドも定義してみましょう。 作成するファイルは以下のとおりです。
Daoの作成
package examples.dao;
import java.util.List;
public interface EmployeeAutoDao {
public Class BEAN = Employee.class;
public List getAllEmployees();
public String getEmployeeByJobDeptno_ARGS = "job, deptno";
public List getEmployeeByJobDeptno(String job, Integer deptno);
public String getEmployeeByEmpno_ARGS = "empno";
public Employee getEmployeeByEmpno(int empno);
public String getEmployeesBySal_QUERY = "sal BETWEEN ? AND ? ORDER BY empno";
public List getEmployeesBySal(float minSal, float maxSal);
public String getEmployeeByDname_ARGS = "dname_0";
public List getEmployeeByDname(String dname);
public List getEmployeesBySearchCondition(EmployeeSearchCondition dto);
public void update(Employee employee);
}
DTOの作成
package examples.dao;
public class EmployeeSearchCondition {
public static final String dname_COLUMN = "dname_0";
private String job;
private String dname;
public String getDname() {
return dname;
}
public void setDname(String dname) {
this.dname = dname;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
}
diconファイルの作成
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE components PUBLIC "-//SEASAR//DTD S2Container//EN"
"http://www.seasar.org/dtd/components.dtd">
<components>
<include path="dao.dicon"/>
<component class="examples.dao.EmployeeAutoDao">
<aspect>dao.interceptor</aspect>
</component>
</components>
実行ファイルの作成
package examples.dao;
import java.util.List;
import org.seasar.framework.container.S2Container;
import org.seasar.framework.container.factory.S2ContainerFactory;
public class EmployeeAutoDaoClient {
private static final String PATH = "examples/dao/EmployeeAutoDao.dicon";
public static void main(String[] args) {
S2Container container = S2ContainerFactory.create(PATH);
container.init();
try {
EmployeeAutoDao dao = (EmployeeAutoDao) container
.getComponent(EmployeeAutoDao.class);
dao.getEmployeeByJobDeptno(null, null);
dao.getEmployeeByJobDeptno("CLERK", null);
dao.getEmployeeByJobDeptno(null, new Integer(20));
dao.getEmployeeByJobDeptno("CLERK", new Integer(20));
List employees = dao.getEmployeesBySal(0, 1000);
for (int i = 0; i < employees.size(); ++i) {
System.out.println(employees.get(i));
}
employees = dao.getEmployeeByDname("SALES");
for (int i = 0; i < employees.size(); ++i) {
System.out.println(employees.get(i));
}
EmployeeSearchCondition dto = new EmployeeSearchCondition();
dto.setDname("RESEARCH");
employees = dao.getEmployeesBySearchCondition(dto);
for (int i = 0; i < employees.size(); ++i) {
System.out.println(employees.get(i));
}
Employee employee = dao.getEmployeeByEmpno(7788);
System.out.println("before timestamp:" + employee.getTimestamp());
dao.update(employee);
System.out.println("after timestamp:" + employee.getTimestamp());
} finally {
container.destroy();
}
}
}
実行結果
DEBUG 2004-10-12 11:35:22,054 [main] 物理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:22,069 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:22,897 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:35:23,726 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno
DEBUG 2004-10-12 11:35:23,726 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,866 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:35:23,866 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno WHERE EMP.job = 'CLERK'
DEBUG 2004-10-12 11:35:23,866 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,882 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:35:23,882 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno WHERE EMP.deptno = 20
DEBUG 2004-10-12 11:35:23,882 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,913 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:35:23,913 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno WHERE EMP.job = 'CLERK' AND EMP.deptno = 20
DEBUG 2004-10-12 11:35:23,913 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,929 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-12 11:35:23,929 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno WHERE sal BETWEEN 0.0 AND 1000.0 ORDER BY empno
DEBUG 2004-10-12 11:35:23,929 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,944 [main] 論理的なコネクションを閉じました
7369, SMITH, CLERK, 7902, 1980-12-17 00:00:00.0, 800.0, null, 20, 1980-12-17 00:00:00.0
{20, RESEARCH, DALLAS, 0}
7900, JAMES, CLERK, 7698, 1981-12-03 00:00:00.0, 950.0, null, 30, 1980-12-17 00:00:00.0
{30, SALES, CHICAGO, 0}
DEBUG 2004-10-12 11:35:23,944 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno WHERE department.dname = 'SALES'
DEBUG 2004-10-12 11:35:23,944 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,960 [main] 論理的なコネクションを閉じました
7499, ALLEN, SALESMAN, 7698, 1981-02-20 00:00:00.0, 1600.0, 300.0, 30, 1980-12-17 00:00:00.0
{30, SALES, CHICAGO, 0}
7521, WARD, SALESMAN, 7698, 1981-02-22 00:00:00.0, 1250.0, 500.0, 30, 1980-12-17 00:00:00.0
{30, SALES, CHICAGO, 0}
7654, MARTIN, SALESMAN, 7698, 1981-09-28 00:00:00.0, 1250.0, 1400.0, 30, 1980-12-17 00:00:00.0
{30, SALES, CHICAGO, 0}
7698, BLAKE, MANAGER, 7839, 1981-05-01 00:00:00.0, 2850.0, null, 30, 1980-12-17 00:00:00.0
{30, SALES, CHICAGO, 0}
7844, TURNER, SALESMAN, 7698, 1981-09-08 00:00:00.0, 1500.0, 0.0, 30, 1980-12-17 00:00:00.0
{30, SALES, CHICAGO, 0}
7900, JAMES, CLERK, 7698, 1981-12-03 00:00:00.0, 950.0, null, 30, 1980-12-17 00:00:00.0
{30, SALES, CHICAGO, 0}
DEBUG 2004-10-12 11:35:23,960 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno WHERE department.dname = 'RESEARCH'
DEBUG 2004-10-12 11:35:23,976 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,976 [main] 論理的なコネクションを閉じました
7369, SMITH, CLERK, 7902, 1980-12-17 00:00:00.0, 800.0, null, 20, 1980-12-17 00:00:00.0
{20, RESEARCH, DALLAS, 0}
7566, JONES, MANAGER, 7839, 1981-04-02 00:00:00.0, 2975.0, null, 20, 1980-12-17 00:00:00.0
{20, RESEARCH, DALLAS, 0}
7788, SCOTT, ANALYST, 7566, 1982-12-09 00:00:00.0, 3000.0, null, 20, 2004-10-12 10:15:54.914
{20, RESEARCH, DALLAS, 0}
7876, ADAMS, CLERK, 7788, 1983-01-12 00:00:00.0, 1100.0, null, 20, 1980-12-17 00:00:00.0
{20, RESEARCH, DALLAS, 0}
7902, FORD, ANALYST, 7566, 1981-12-03 00:00:00.0, 3000.0, null, 20, 1980-12-17 00:00:00.0
{20, RESEARCH, DALLAS, 0}
DEBUG 2004-10-12 11:35:23,976 [main] SELECT EMP.tstamp, EMP.empno, EMP.ename, EMP.job, EMP.mgr,
EMP.hiredate, EMP.sal, EMP.comm, EMP.deptno, department.dname AS dname_0, department.deptno AS deptno_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP LEFT OUTER JOIN DEPT department
ON EMP.deptno = department.deptno WHERE EMP.empno = 7788
DEBUG 2004-10-12 11:35:23,991 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,991 [main] 論理的なコネクションを閉じました
before timestamp:2004-10-12 10:15:54.914
DEBUG 2004-10-12 11:35:23,991 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-12 11:35:23,991 [main] UPDATE EMP SET tstamp = '2004-10-12 11.35.23', ename = 'SCOTT',
job = 'ANALYST', mgr = 7566, hiredate = '1982-12-09 00.00.00', sal = 3000.0, comm = null, deptno = 20
WHERE empno = 7788 AND tstamp = '2004-10-12 10.15.54'
DEBUG 2004-10-12 11:35:24,054 [main] 論理的なコネクションを閉じました
after timestamp:2004-10-12 11:35:23.991
DEBUG 2004-10-12 11:35:24,054 [main] 物理的なコネクションを閉じました
出力されているログからSQL文が自動的に生成されていることがわかります。 EntityManagerを使用したExampleEntityManagerを使用して、指定した文字列を名前に含む従業員を検索する演習です。
Daoの作成
package examples.dao;
import java.util.List;
public interface Employee2Dao {
public Class BEAN = Employee.class;
public List getEmployees(String ename);
}
AbstractDaoを継承したクラスの作成
package examples.dao;
import java.util.List;
import org.seasar.dao.DaoMetaDataFactory;
import org.seasar.dao.impl.AbstractDao;
public class Employee2DaoImpl extends AbstractDao implements Employee2Dao {
public Employee2DaoImpl(DaoMetaDataFactory daoMetaDataFactory) {
super(daoMetaDataFactory);
}
public List getEmployees(String ename) {
return getEntityManager().find("ename LIKE ?", "%" + ename + "%");
}
}
diconファイルの作成
<?xml version="1.0" encoding="Shift_JIS"?>
<!DOCTYPE components PUBLIC "-//SEASAR//DTD S2Container//EN"
"http://www.seasar.org/dtd/components.dtd">
<components>
<include path="dao.dicon"/>
<component class="examples.dao.Employee2DaoImpl">
<aspect>dao.interceptor</aspect>
</component>
</components>
実行ファイルの作成
package examples.dao;
import java.util.List;
import org.seasar.framework.container.S2Container;
import org.seasar.framework.container.factory.S2ContainerFactory;
public class Employee2DaoClient {
private static final String PATH = "examples/dao/Employee2Dao.dicon";
public static void main(String[] args) {
S2Container container = S2ContainerFactory.create(PATH);
container.init();
try {
Employee2Dao dao = (Employee2Dao) container
.getComponent(Employee2Dao.class);
List employees = dao.getEmployees("CO");
for (int i = 0; i < employees.size(); ++i) {
System.out.println(employees.get(i));
}
} finally {
container.destroy();
}
}
}
実行結果
DEBUG 2004-10-01 10:14:39,333 [main] 物理的なコネクションを取得しました
DEBUG 2004-10-01 10:14:39,333 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-01 10:14:40,379 [main] 論理的なコネクションを閉じました
DEBUG 2004-10-01 10:14:41,254 [main] SELECT EMP.empno, EMP.ename, EMP.job, EMP.mgr, EMP.hiredate,
EMP.sal, EMP.comm, EMP.deptno, department.deptno AS deptno_0, department.dname AS dname_0,
department.loc AS loc_0, department.versionNo AS versionNo_0 FROM EMP
LEFT OUTER JOIN DEPT department ON EMP.deptno = department.deptno WHERE ename LIKE '%CO%'
DEBUG 2004-10-01 10:14:41,270 [main] 論理的なコネクションを取得しました
DEBUG 2004-10-01 10:14:41,426 [main] 論理的なコネクションを閉じました
7788, SCOTT, ANALYST, 7566, 1982-12-09 00:00:00.0, 3000.0, null, 20 {20, RESEARCH, DALLAS, 0}
DEBUG 2004-10-01 10:14:41,442 [main] 物理的なコネクションを閉じました
この演習は、s2dao/src/examples/dao以下に用意されています。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| © Copyright The Seasar Foundation and the others 2004-2011, all rights reserved. |